美团大模型来了!开源“长猫”,性能追平DeepSeek V3.1,同样主打“算力
LongCat-Flash推理速度超过100词元/秒,每处理一百万输出词元的成本仅为0.7美元。该模型不仅在多个方面与DeepSeek V3.1、Qwen3等顶尖模型旗鼓相当,甚至在某些特定能力上实现了超越。比如,在执行“智能代理”(Agent)任务方面的能力测试中,LongCat-Flash的得分在所有参与对比的模型中排名第一。
它不仅在性能上追求卓越,更通过一系列架构和训练上的创新,实现了惊人的计算效率和高级的Agent能力。
模型可以智能地判断输入内容中不同部分的重要性,并将计算量较小的任务(例如常见的词语、标点符号)分配给一个特殊的“零计算”专家。
得益于此,模型在处理每个词元(token)时,仅需动态激活186亿至313亿的参数(平均约270亿),实现了性能与效率的完美平衡。
ScMoE架构通过引入一个快捷连接,有效地扩大了计算和通信的重叠窗口,显著提升了训练和推理的吞吐量,让模型的响应速度更快。
为了让模型不仅能“聊天”,更能成为能解决复杂任务的“智能代理”,LongCat-Flash经历了一个精心设计的为Agent而生的多阶段训练流程。
该流程包括大规模预训练、针对性地提升推理和代码能力的中期训练deepseek,以及专注于对话和工具使用能力的后训练。
一个有趣且值得关注的细节是,在官方的技术报告中,强调了LongCat-Flash是在一个包含数万个加速器(tens of thousands of accelerators)的大规模集群上完成训练的。
在当前AI领域,虽然大家通常会立刻联想到NVIDIA的GPU,但“加速器”是一个更广泛的概念,它可以包括Google的TPU、华为的昇腾(Ascend)或其他专为AI计算设计的芯片。
官方选择使用这个词汇,而没有明确指出是“GPU”,这为硬件的具体来源留下了一定的想象空间,也体现了其在技术陈述上的精确性。
无论具体是哪种硬件,在如此庞大的集群上,于短短30天内完成超过20万亿词元的训练量,都足以证明其背后基础设施的强大与工程优化的卓越。
强大的综合能力 :支持128k的长文本上下文,并在代码、推理和工具调用等多个方面展现出与业界领先模型相媲美的竞争力。
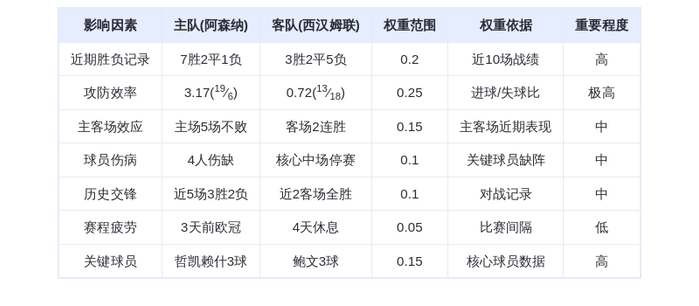
为了更直观地展示 LongCat-Flash 的实力,我们来看一下它与业界其他顶尖模型的详细评估对比。
美团的 LongCat-Flash 模型在各项基准测试中展现出了非常强劲且极具竞争力的性能。
它不仅在多个方面与业界顶尖的开源模型(如 DeepSeek V3.1, Qwen3)旗鼓相当,甚至在某些特定能力上实现了超越。
这个基准更侧重于模型作为聊天助手的“体感”和处理复杂指令的能力。LongCat-Flash 在此项得分 86.50 ,超过了 DeepSeek V3.1,与 Qwen3 MoE(88.20)非常接近,这说明它的对话和推理能力非常优秀。
作为中文领域的权威测试,LongCat-Flash 在 CEval 上表现优异(90.44),在 CMMLU 上也保持了不错的水平,证明其对中文语言有很好的支持。
这强有力地证明了它在执行需要调用工具、与环境交互的复杂“智能代理”(Agent)任务方面的卓越能力。
全球学术界和产业界的研究者、开发者都可以自由地使用和探索这个强大的模型,共同推动AI技术的发展。
本文来源:01Founder,原文标题:《突发,美团开源龙猫大模型,性能追平DeepSeek!》
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。原文出处:美团大模型来了!开源“长猫”,性能追平DeepSeek V3.1,同样主打“算力节省”,感谢原作者,侵权必删!