

DeepSeek新模型让AI成本砍半!长文本处理效率暴增的秘密在这
今天早上七点多,我正刷着牙呢,手机突然弹出一条消息:DeepSeek发布全新V3.2-Exp模型。本来以为又是哪个公司在吹牛皮,结果点开一看,我牙刷差点掉洗手池里——这玩意儿不仅性能更强,

说真的,做AI开发的都知道,大模型API调用费用简直就是个无底洞。我之前有个项目,一个月光API费用就烧了小一万,老板天天盯着我问“能不能省点”。

现在DeepSeek直接来了个王炸:新模型API价格即时生效,直接打对折!这意味着啥?意味着同样的预算,你现在能做的事情直接翻倍。我那些搞创业的朋友听到这消息,激动地差点把群聊刷爆了。
但最让我惊讶的不是降价,而是在降价的同时,性能居然还提升了?这不符合常理啊!一般公司都是性能提升价格跟着涨,DeepSeek这是要当行业价格屠夫?

仔细研究了一下,才发现奥秘全在那个新推出的DeepSeek稀疏注意力机制(DSA)上。这玩意儿可是基于北大ACL最佳论文改进而来的,含金量十足!
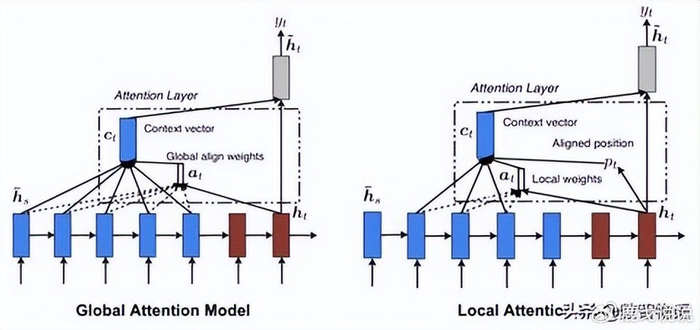
简单来说,传统的注意力机制就像是个强迫症——每个词都要关注序列中的所有其他词,计算量大得吓人。而DSA机制聪明得很,它有个叫“闪电索引器”的东西,能快速判断哪些词才是最重要的,然后只关注这些关键词。
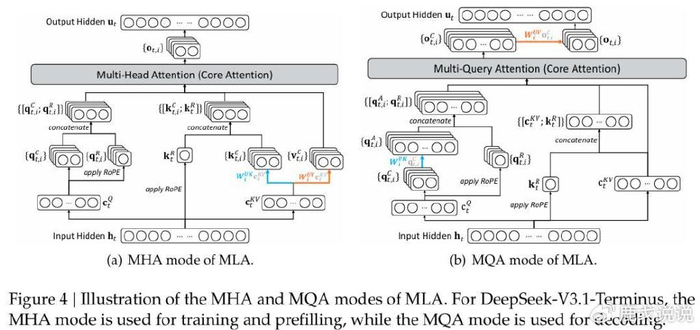
这就好比你看书的时候,不是每个字都仔细读,而是快速扫视找重点。效率自然就上去了,而且效果居然差不多!
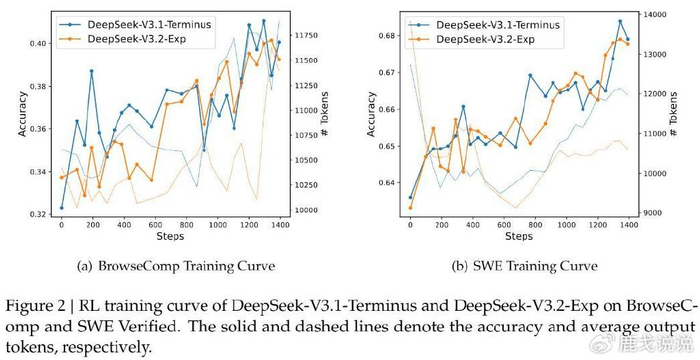
我们做开发的都知道,处理长文本一直是个头疼的问题。之前用其他模型处理长文档,速度慢不说,费用还死贵。现在DeepSeek-V3.2-Exp在长上下文训练和推理方面实现了更快、更高效的表现,这简直是我们的福音啊!
实测数据显示,新模型在处理长文本时的效率提升非常明显。计算复杂度从原来的O(L²)直接降到O(Lk),这个提升幅度可不是闹着玩的。意味着以后处理那些动辄上万字的文档,速度和成本都能优化一大截。
更让人兴奋的是,DeepSeek这次直接把V3.2-Exp开源了!开源地址都已经放在GitHub上,任何人都可以免费使用。这波操作直接让开源社区沸腾了。

说实话,现在很多大厂都把最好的模型捂得严严实实,DeepSeek这波开源真的很拉好感。毕竟开源才能推动整个行业进步,我们这些开发者也能跟着受益。
不得不说的是,这个DSA机制可是有学术背书的。它基于北大ACL最佳论文提出的原生稀疏注意力(NSA)改进而来,这可是自然语言处理领域的顶级会议啊!
论文地址已经在GitHub上公开,感兴趣的技术同仁可以去深入研究。我粗略看了一下,里面的数学推导相当精彩,不愧是顶级学术成果的产业化应用。
拿到API权限后,我立马做了个测试。用同样的任务对比新老模型,结果让我惊掉了下巴——效果基本持平,但响应速度明显更快,关键是费用直接减半!

我的一个项目原本月API费用要8000多,现在用新模型,同样工作量只需要3000多。这省下来的5000块,够我给团队发多少奖金啊!而且处理长文档时,那个速度提升感知特别明显。
DeepSeek这波操作,估计要让很多友商睡不着觉了。毕竟在AI开发成本高企的当下,谁能把成本打下来,谁就能获得开发者的拥戴。
而且这种“性能不降、成本骤减”的模式,很可能成为行业新标准。其他厂商要是跟不上,估计会被开发者们用脚投票抛弃掉。
我的建议是:赶紧去申请API权限体验一下deepseek!反正现在价格这么便宜,不用白不用。特别是那些需要处理长文本的项目,绝对值得一试。

如果你还在为API费用发愁,现在真的是个好时机。趁着其他厂商还没跟进降价,先用DeepSeek的新模型把成本降下来,这在商业上就是竞争优势啊!
不过也要冷静看待,新模型毕竟还标着“实验性”的标签。虽然目前测试下来效果不错,但在生产环境中还是要做好充分的测试和验证。
但无论如何,DeepSeek这波操作确实给行业带来了新的活力和可能性。作为开发者,我是乐见其成的,毕竟谁能拒绝既便宜又好用的工具呢?原文出处:DeepSeek新模型让AI成本砍半!长文本处理效率暴增的秘密在这,感谢原作者,侵权必删!
